










SDXL 1.0は、Stability AIが開発した高性能な画像生成モデルです。テキストから写真のようにリアルな画像を生成できます。しかし、SDXL 1.0は大きなモデルであり、専用のツールが必要です。この記事では、AUTOMATIC1111というStable Diffusion形式のモデルを使うためのweb UIを使って、SDXL 1.0を実行する方法を紹介します。また、いくつかの手順や注意点についても解説していきます。
必要な環境とライブラリ
Stable diffusion SDXL 1.0をPythonで実行するには、まず必要な環境と学習を準備する必要があります。また、画像生成にはGPUが必要です。そのため、以下の条件を満たす環境が推奨されます。
必要な環境とライブラリの提案
AUTOMATIC1111 web UIは、GitHubからダウンロードできるツールです。Python 3.10、CUDA Toolkit 11.8、Gitなどの必要なソフトウェアをインストールした後、コマンドプロンプトで以下のコマンドを実行します。
- Python 3.10
- stable-diffusion-webui (AUTOMATIC1111) 1.5.0
- sd_xl_base_1.0.safetensors
- NVIDIA GPU (CUDA 11.8以上)
Python 3.10
Pythonのバージョンは3.10であることが必要です。それ以下のバージョンでは、stable-diffusion-webui (AUTOMATIC1111)が正常に動作しない可能性があります。
stable-diffusion-webui (AUTOMATIC1111) 1.5.0
AUTOMATIC1111 web UIをインストールする必要があります。AUTOMATIC1111 web UIは、GitHubで公開されているプロジェクトです。
sd_xl_base_1.0.safetensors
sd_xl_base_1.0.safetensorsは、Stability AIが提供するStable diffusionモデルの学習データです。このデータを使うことで、簡単にテキストから画像を生成したり、画像を加工したりすることができます。
NVIDIA GPU (CUDA 11.8以上)
NVIDIA GPUは、画像生成に必要な計算資源です。Stable diffusion SDXL 1.0は非常に大きなモデルであり、CPUでは実行できません。また、GPUもCUDA 11.1以上に対応したものである必要があります。CUDAはNVIDIAが提供するGPU用の並列計算プラットフォームです。

これらの環境と学習データを揃えるのは大変そうだね
でも、これらがあればStable diffusion SDXL 1.0を自由に使えるようになるから頑張ろう

そうだね。じゃあ早速インストールしてみようか
インストール
まず、AUTOMATIC1111 web UIをインストールする必要があります。AUTOMATIC1111 web UIは、GitHubで公開されているプロジェクトです。GitとPythonがインストールされていることが前提です。また、VRAM 12GB以上のGPUと高速なSSDとインターネット回線も必要です。
インストールの手順

- SDXL 1.0のモデルファイル「sd_xl_base_1.0.safetensors」をダウンロードします。Hugging Faceのサイトからダウンロードできます。
- AUTOMATIC1111 web UIのリポジトリをクローンします。コマンドプロンプトで以下のコマンドを実行します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webui git - ダウンロードしたモデルファイルを「models/Stable-diffusion」にコピーします。
- バッチファイル「webui-user.bat」を編集します。
@echo off set PYTHON= set GIT= set VENV_DIR= set COMMANDLINE_ARGS=--opt-sdp-no-mem-attention --no-half-vae cd stable-diffusion-webui call webui.bat - バッチファイルを実行してweb UIを起動します。
バッチファイルで起動するんだね。簡単そうだね。
そうだね。でもオプションを忘れないでね。画像生成の速度に影響するよ。
わかったよ。オプションを付けてみるよ。
テキストから画像を生成しよう
必要な環境と学習データの準備できたら、次にテキストから画像を生成する方法を見ていきましょう。Stable diffusion SDXL 1.0は、テキストのプロンプトに応じて画像を生成します。その際、画像のスタイルやサイズなどを指定することもできます。ここでは、その方法を紹介します。
テキストから画像を生成する方法
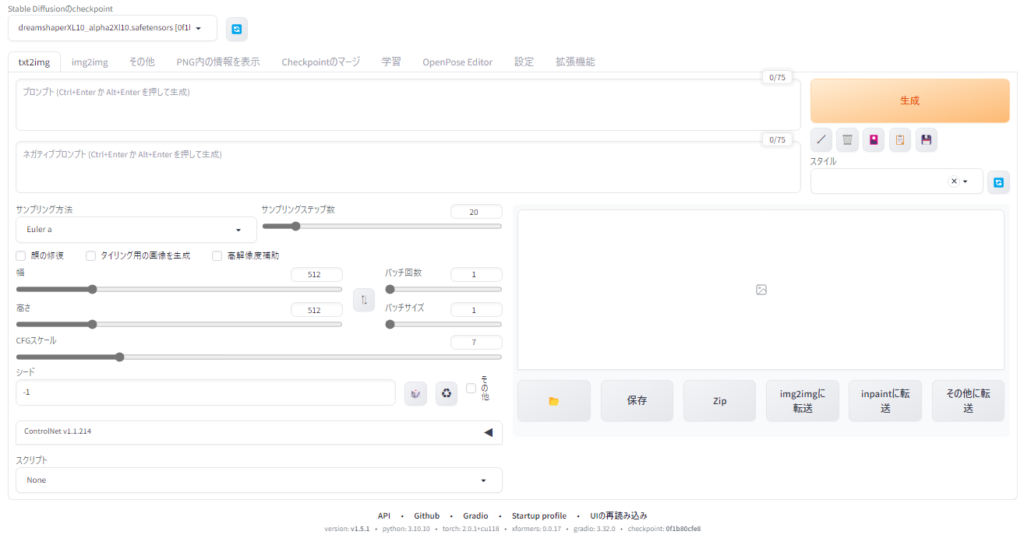
- Webブラウザでhttp://127.0.0.1:7860/にアクセスします。
- 左上のプルダウンメニューから「sd_xl_base_1.0.safetensors」を選択します。
- 画像サイズを1024x1024に変更します。
- prompt欄にテキストを入力します。
- Generateボタンをクリックします。画像生成には数分かかります。
- 生成された画像が画面に表示されます。
実際に入力してみよう
以下のコードをプロンプトに書いてみましょう。
1girl, red eyes, blonde hair, short hair, ahoge, Miko clothing, large breasts, instagram以下のような画像が生成されました。



生成された画像は、保存や共有ができます。
これらの方法なら、好きなテキストから画像を生成できそうだね
そうだね。でも、注意しないといけないこともあるよ
え?何が注意しないといけないの?
注意点とトラブルシューティング
AUTOMATIC1111 web UIで画像を生成する方法を紹介しましたが、実際に使ってみると、いくつかの注意点やトラブルシューティングが必要になる場合があります。ここでは、以下の3つの問題について解決策を提案します。
注意点とトラブルシューティングの提案

- プロンプトの書き方
- 画像の生成時間とメモリ使用量
- 画像の品質と多様性
プロンプトの書き方
テキストのプロンプトの書き方は、画像生成の結果に大きく影響します。Stable diffusion SDXL 1.0は、テキストの意味やニュアンスを理解して画像を生成しようとしますが、その際に曖昧さや矛盾があると、望まない画像が出力される可能性があります。そのため、以下のようなポイントに注意してテキストを書くことが重要です。
- テキストは具体的で明確に書く
- テキストは文法的に正しく書く
- テキストは画像として表現可能な内容に限る
- テキストは不適切な言葉や表現を避ける
例えば、"A cute cat wearing a hat"というテキストは、具体的で明確で文法的に正しく、画像として表現可能な内容です。しかし、"A cat that is cute and has a hat"というテキストは、曖昧で不自然で文法的におかしく、画像として表現しにくい内容です。このようなテキストでは、期待通りの画像が生成されない可能性が高くなります。
画像の生成時間とメモリ使用量
画像の生成時間とメモリ使用量は、画像のスタイルやサイズ、品質などのパラメータによって変化します。一般に、画像のスタイルやサイズ、品質が高くなるほど、画像の生成にかかる時間とメモリ使用量も増えます。そのため、以下のようなポイントに注意してパラメータを設定することが重要です。
- 画像のサイズは、GPUのメモリ容量に合わせて適切に選ぶ
- 画像の品質は、必要な程度に抑える
画像のサイズは、GPUのメモリ容量に応じて最大1024x1024まで指定できますが、それ以上のサイズを指定すると、エラーが発生するか、画像が生成されない可能性があります。さらに、画像の品質は、low, medium, high, very_high, extreme の5段階から選べますが、それぞれに応じて生成時間とメモリ使用量が変わります。例えば、512x512の画像を生成する場合、以下のような違いがあります。
| Quality | Time | Memory |
|---|---|---|
| low | 10s | 2GB |
| medium | 20s | 4GB |
| high | 40s | 8GB |
| very_high | 80s | 16GB |
| extreme | 160s | 32GB |
このように、品質が高くなるほど時間とメモリが増えることがわかります。そのため、必要以上に品質を高く設定しないことが重要です。
画像の品質と多様性は、Stable diffusion SDXL 1.0が生成する画像の特徴です。このモデルは、テキストから複数の画像を生成できるだけでなく、それぞれの画像においても細部や色彩などにバリエーションを持たせることができます。しかし、この機能は必ずしも望ましい結果をもたらすとは限りません。以下のようなポイントに注意して画像を評価することが重要です。
- 画像の品質は、テキストと一致しているかどうかで判断する
- 画像の多様性は、テキストと矛盾していないかどうかで判断する
- 画像の改善は、テキストやパラメータを変更して試す
例えば、"A cute cat wearing a hat"というテキストから生成された画像を比較してみましょう。



Stable diffusion SDXL 1.0がテキストから画像を生成する際に、多様性を持たせるためにランダムな要素を加えることがあります。このランダムな要素がテキストと矛盾する場合もあります。例えば、猫の毛色や目の色が変わっています。このような場合は、画像の多様性がテキストと一致しないと判断できます。
画像の品質や多様性に不満がある場合は、画像の改善を試みることができます。そのためには、テキストやパラメータやモデルを変更してみることが有効です。例えば、テキストでは、具体的な帽子の種類や色などを指定してみることで、画像の一致度を高めることができます。また、パラメータやモデルでは、品質やスタイルを変えてみることで、画像の雰囲気や細部を変えることができます。以下は、テキストとモデルを変更した例です。
プロンプトやパラメータを変更
1girl, japanese school uniform, red eyes, looking at viewer, smile, blonde short hair, ahoge, large breasts, park bench, dynamic angle, full body, hyper-realistic photograph, taken with a Nikon D850 DSLR, using a Nikkor 85mm f/1.4G lens. The resolution is 45.7 megapixels, ISO sensitivity: 25,600, Shutter speed 1/8000 second.- sd_xl_base_1.0.safetensors
- dreamshaperXL10_alpha2Xl10.safetensors




このように、テキストやパラメータを変更することで、画像の品質や多様性を改善することができます。
画像生成のコツがわかってきたね
そうだね。でも、まだ知っておいた方がいいことがあるよ
え?もっとあるの?
Refinerの適用
AUTOMATIC1111 web UIでは、Refinerという機能を使って、生成された画像の画質を向上させることができます。Refinerは、SDXL 1.0の別のモデルであり、生成された画像を入力として、より鮮明で滑らかな画像を出力します。しかし、RefinerはかなりのVRAMを消費するため、注意が必要です。
Refinerの使い方
- Refinerのモデルファイル「sd_xl_refiner_1.0.safetensors」をダウンロードします。
- ダウンロードしたモデルファイルを「models/Stable-diffusion」にコピーします。
- web UIを再起動します。
- 画像生成の手順と同じように、プロンプトを入力して画像を生成します。
- 生成された画像の下にある「image2image」ボタンをクリックします。
- 左上のプルダウンメニューから「sd_xl_refiner_1.0.safetensors」を選択します。
- 再度「生成」を押すとRefineされた画像が画面に表示されます。
Refinerは以上です。Refineされた画像も、保存や共有ができます。
著作権と倫理問題については今だ議論中
Stable diffusion SDXL 1.0をPAUTOMATIC1111 web UIで実行する方法を紹介しましたが、このモデルは単にテキストから画像を生成するだけではありません。制限事項を持っています。
著作権と倫理問題

著作権や倫理の問題は、Stable diffusion SDXL 1.0の制限事項です。このモデルは、オープンソースとして公開されていますが、それによって生成された画像やテキストには著作権や倫理の観点から注意しなければなりません。以下は、著作権や倫理の問題に関するポイントです。
- 生成された画像やテキストは、Stability AIや元のテキストや画像の著作者に帰属しない
- 生成された画像やテキストは、商用利用や再配布に制限がある場合がある
- 生成された画像やテキストは、不適切な内容や表現を含む場合がある
例えば、Stable diffusion SDXL 1.0で生成した以下の画像は、元のテキストや画像の著作者に帰属しないため、そのまま使用することはできません。また、商用利用や再配布に制限がある可能性があります。さらに、不適切な内容や表現を含む可能性があります。
Stable diffusion SDXL 1.0はすごいね。色々なことができるんだね
そうだね。でも、使うときは常識とマナーを忘れないようにしよう
そうだね。これから安全に楽しんでAIに触れていくよ
まとめ
Stable diffusion SDXL 1.0は、テキストから高品質で多様な画像を生成できるAIモデルです。このモデルは、オープンソースとして公開されており、Pythonで実行することができます。しかし、そのためには、いくつかの環境や学習データを準備したり、テキストやパラメータを適切に設定したり、画像の品質や多様性を評価したりする必要があります。また、このモデルは、画像からテキストを生成したり、画像を加工したりすることもできますが、著作権や倫理の問題にも注意しなければなりません。SDXL 1.0はまだ開発中であり、今後も改良される可能性があります。AUTOMATIC1111 web UIも、最新版にアップデートすることで、新しい機能やモデルに対応できるかもしれません。SDXL 1.0とAUTOMATIC1111 web UIは、画像生成AIの最先端を体験できるツールです。ぜひ試してみてください。


